
Da oggi sarà possibile ammirare la famosa Notte stellata di Vincent Van Gogh o la celebre Persistenza della memoria di Salvador Dalì senza spostarsi dal proprio divano di casa. O quasi.
Il celebre Museum of Modern Arts (MoMa) di New York è uno dei principali templi della cultura mondiale. Fondato nel 1929 da Abby Aldrich Rockefeller è uno dei primi musei statunitensi a occuparsi interamente di cultura moderna. Oggi, la raccolta del MoMA conta circa 200.000 opere provenienti di oltre 10.000 artisti diversi. Oltre a quadri e sculture sono presenti 22.000 film e centinaia di fotografie d’arte. Tra i capolavori ospitati al suo interno ci sono, oltre a quelli già citati, Les demoiselles d’Avignon di Pablo Picasso, Forme Uniche della continuità nello Spazio di Umberto Boccioni, Canto d’Amore di De Chirico e molte altre ancora.
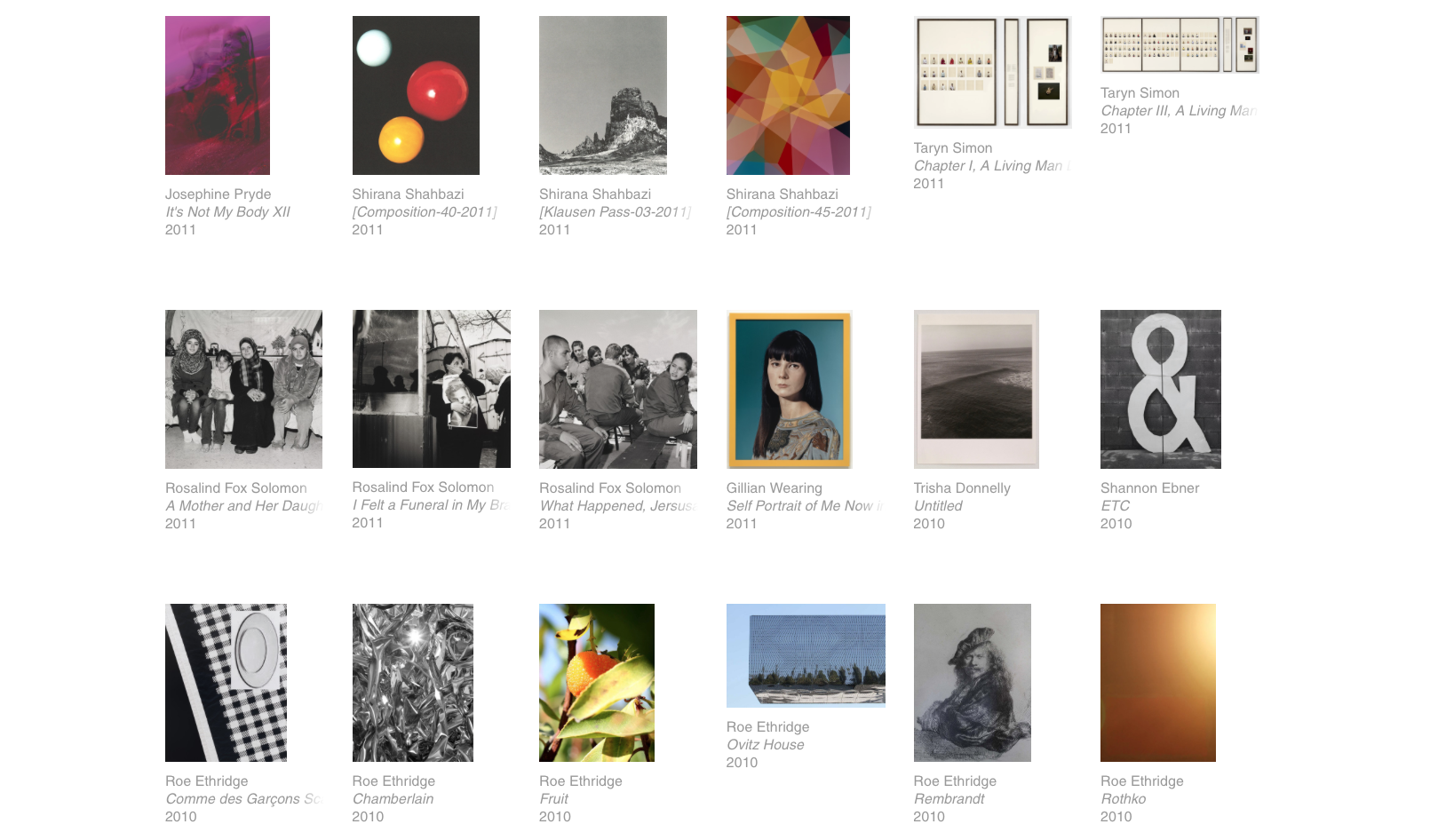
Se, per ragioni di tempo e denaro, non è possibile a tutti visitare il museo e godere in prima persona di questo incredibile patrimonio artistico, il MoMa ha proceduto alla digitalizzazione di ben 67.000 opere realizzate tra il 1860 e il 2016, rendendole fruibili almeno online al pubblico. La consultazione è intuitiva: è possibile filtrare le opere in base alla tipologia (dipinto, scultura…) e al periodo storico.
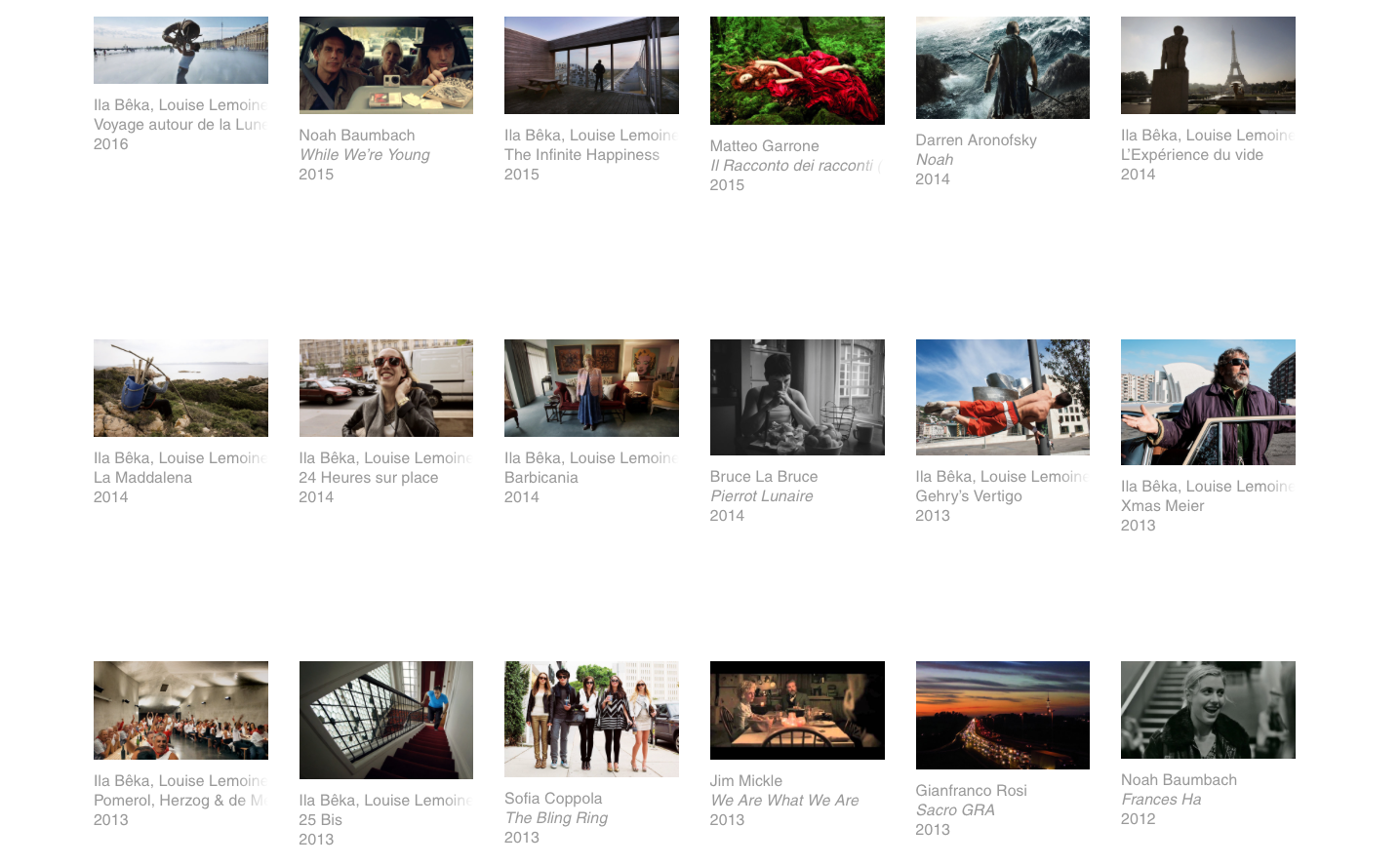
Ma come funziona la codificazione digitale di queste opere d’arte?
Il problema di fronte al quale i tecnici del Moma si sono trovati è quello di garantire che i posteri capiscano che tipo di file si troveranno davanti e capire in che maniera utilizzarlo. In altre parole, anche se riusciamo a mantenere una copia perfetta di un file video per 100 anni, potrebbe succedere che le persone che si troveranno un giorno a utilizzarlo non siano in grado di capire di che tipo di prodotto tecnologico si tratta e come usarlo. Per evitare questo scenario è stato usato un “packager” (letteralmente un “confezionatore”) open-source chiamato Archivematica, che analizza i materiali digitali di tutti i tipi, e registra i risultati in un formato di testo confezionato e conservato con i materiali stessi, utile a capirne la natura. Così da aiutare le future generazioni a comprendere che tipo di “flusso di bit” abbiano di fronte e come usarlo.
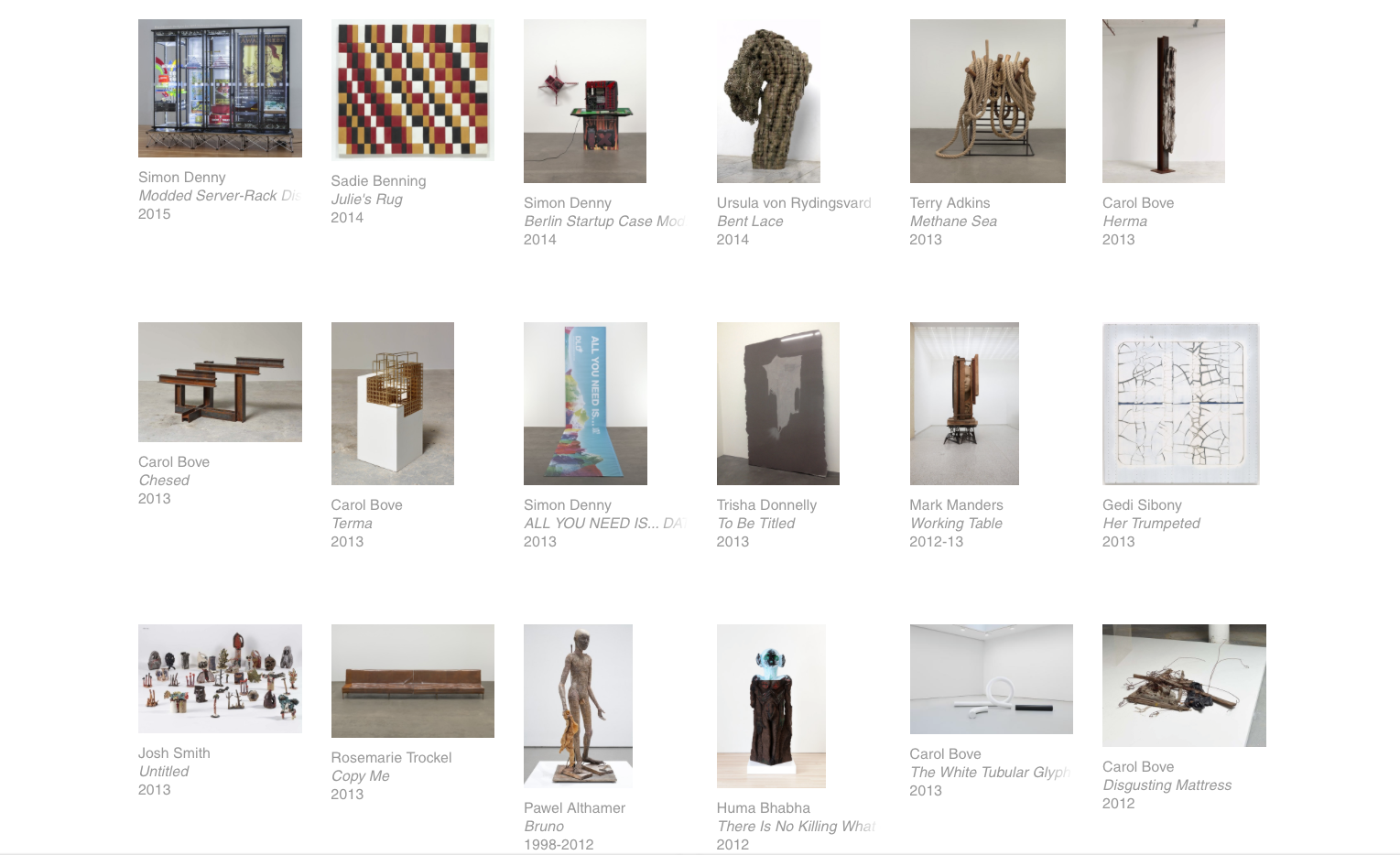
C’è poi la questione dell’autenticità dell’opera. Come possiamo dimostrare in 100 anni che un dato oggetto digitale della collezione non sia stato modificato, né danneggiato? Per risolvere questo problema, il confezionatore assegna a ciascun file digitale un algoritmo chiamato checksum; tale valore ci permette di confrontare lo stesso file a 100 anni di distanza: se la serie di lettere e numeri combacia al 100 per 100 significa che l’oggetto in questione non è stato né manomesso né corrotto.
Questi pacchetti d’archivio vengono poi inviati all’interno di un sistema di archiviazione digitale, chiamato il “magazzino”, gestito dalla divisione infrastrutture del reparto IT del MoMA. Questo magazzino conta attualmente circa 80 terabyte (80.000 gigabyte) ma è stato previsto che entro il 2025 il magazzino arrivi a pesare circa 1,2 petabyte (1,2 milioni di gigabyte). Inoltre, grazie ad una società denominata Archivium, si sta giungendo a un sistema completamente automatizzato e “robotizzato” di raccolta di dati.


